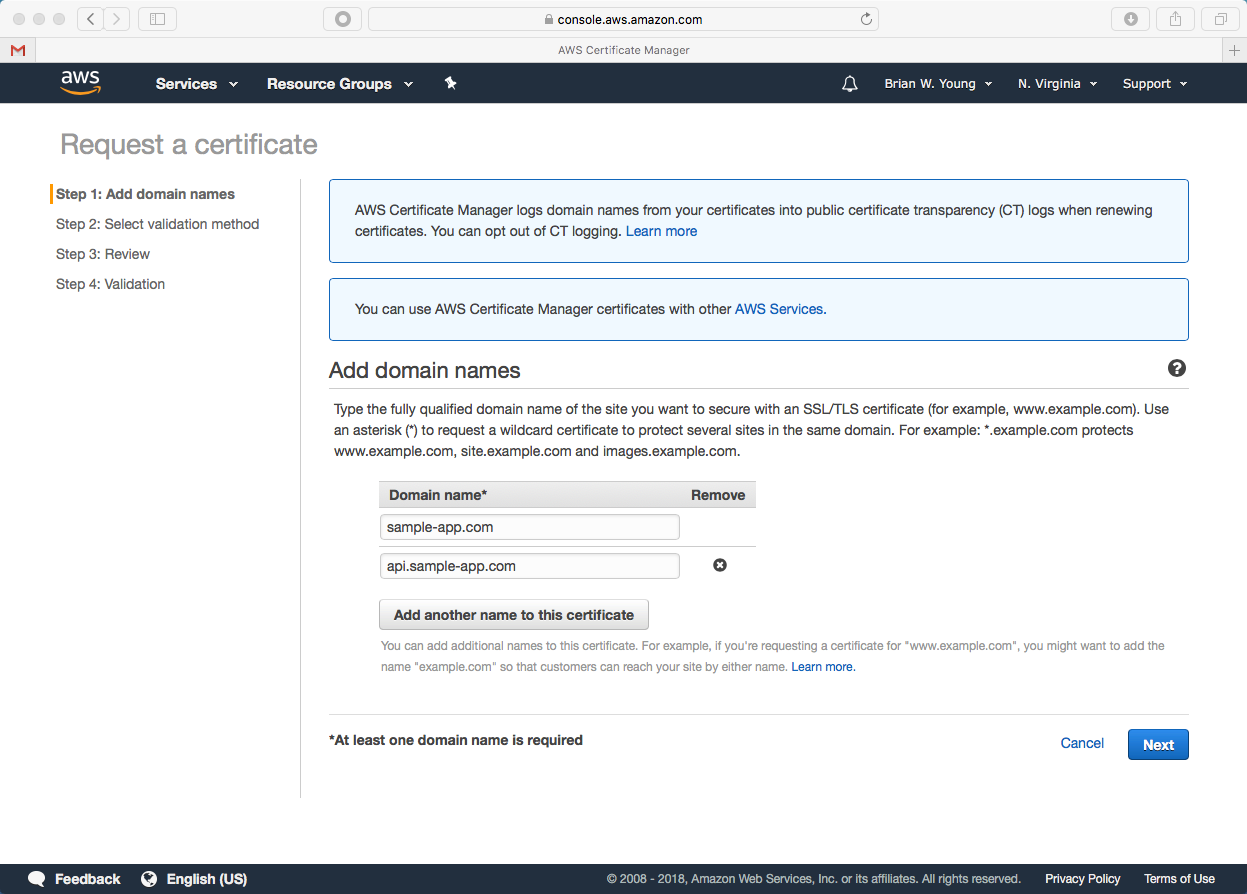
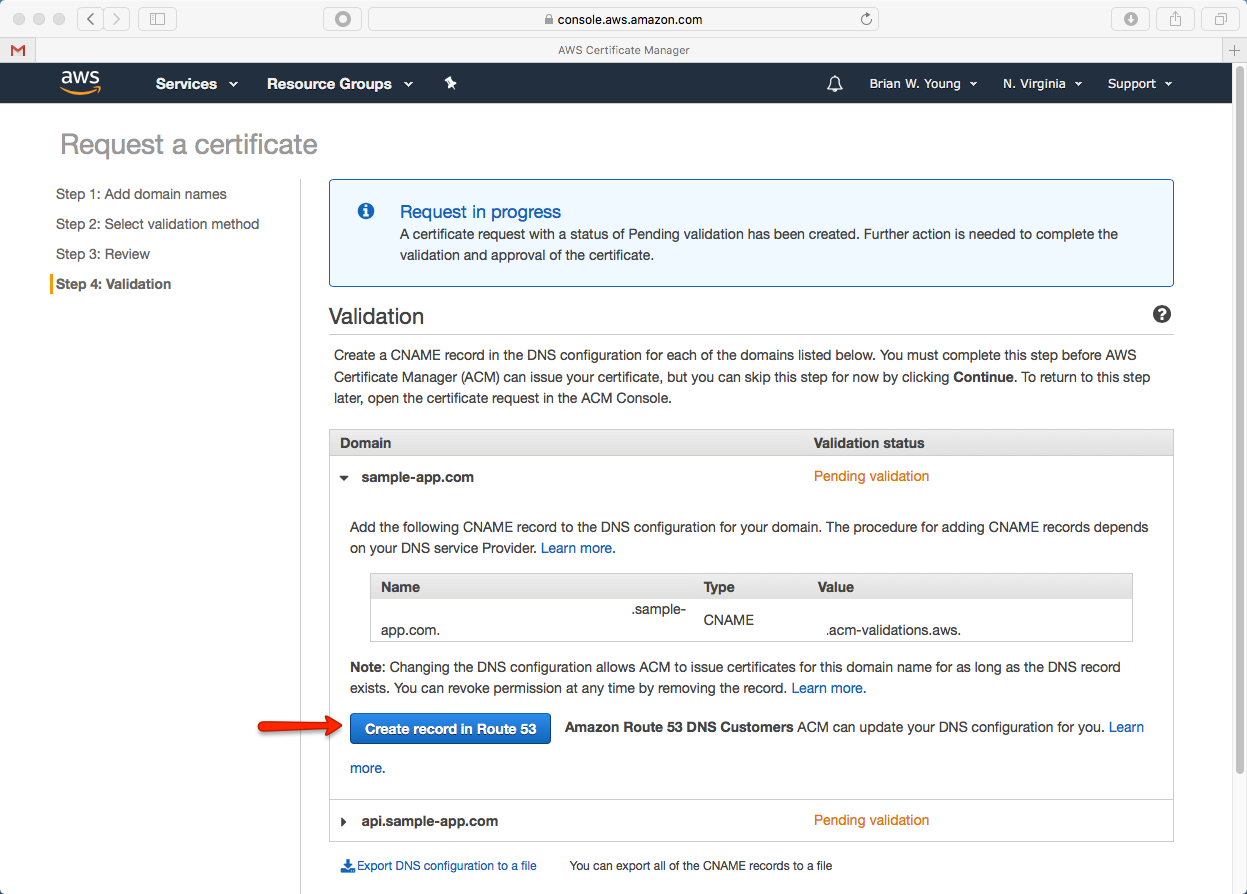
In my previous post, we began the process of hosting an application based on ReactJS, Spring Boot, and MySQL inside of AWS. We handled the prerequisites of registering our domain and obtaining a digital certificate. Now we’re ready to host the back end components of our application.
RDS
Amazon Relational Database Service (RDS) is an easy way to host a relational database inside of AWS. A variety of database types are supported; for this example we’ll be setting up a MySQL instance.
We will create a Dev/Test instance sized at t2.micro since this is just a demonstration exercise. Also, we’ll specify “sample_db” for the initial database. (Schema and Database are analogous in MySQL.)
- The DB instance identifier is arbitrary. However, you may want to give some thought to naming conventions if you’re as OCD about these sorts of things as I am.
- Selecting Publicly accessibility allows us to later whitelist our workstation’s public IP for direct access to the database- for example, via port 3306 from MySQL Workbench.
- Note that this setting name is misleading; the instance isn’t visible to anything outside AWS until specific rules are added.
- username and password will be needed later in order to connect to the database.
- Defaults for the rest of the advanced settings are often fine- I don’t advise changing them unless you have a good reason to do so.
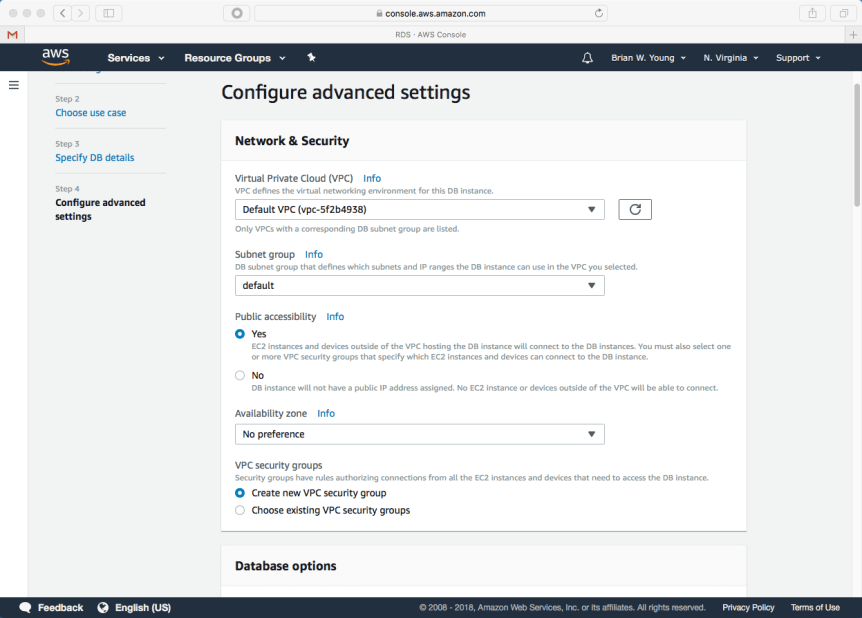
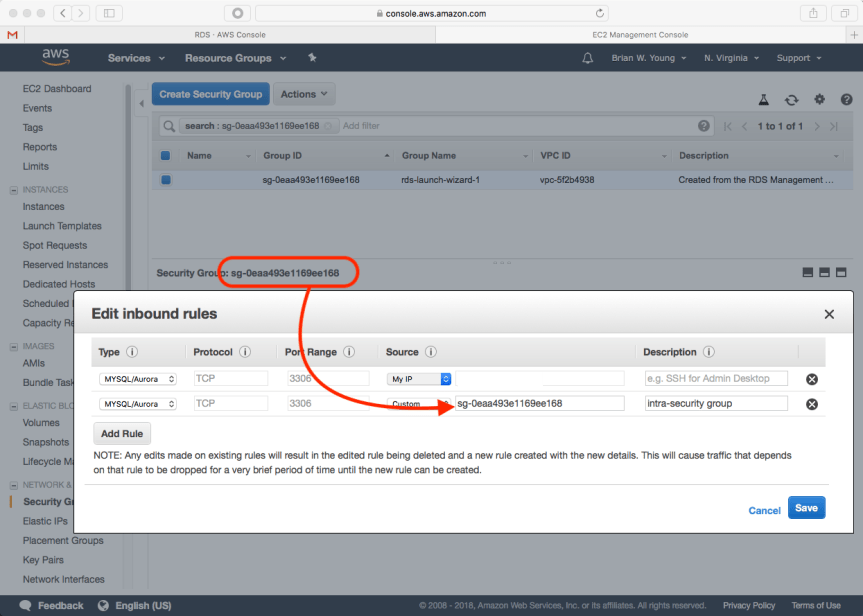
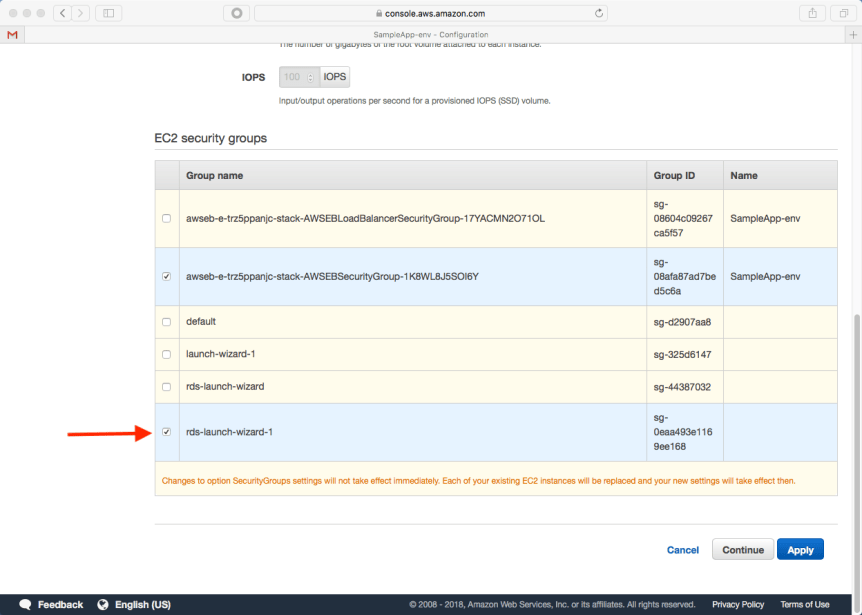
Before we leave RDS, we need to make a security change that will ultimately allow our Spring Boot application in Elastic Beanstalk to communicate with the MySQL instance. We will edit our instance’s security group and add a rule that allows inbound traffic on 3306 from anyone that shares the same security group. We can also add a rule allowing inbound traffic from our workstation.
Elastic Beanstalk
Elastic Beanstalk is a scalable way to deploy web applications on AWS. The Beanstalk’s Java SE environment is a perfect fit for a Spring Boot application. Note that a variety of other application platforms are supported as well.
The sample Spring Boot application we’re using is available at GitHub. Built it with Maven- the result of running mvn install is a single jar file: message-server-1.0-SNAPSHOT.jar. This is the file we will deploy.
First, we need to create a new application inside of Elastic Beanstalk. We’ll simply call it “sample app.”
An application has one or more environments. For example, you might have a dev, qa, and production environment. In this case we’re only creating only one environment. We’ll choose web server environment for the environment type.
- The web server environment setup asks for help in naming the domain. This isn’t especially important in our case since our front end is going to communicate with the back end via api.sample-app.com, not gibberish.us-east-1.elasticbeanstalk.com.
- Select Preconfigured platform: Java.
- Select Application code: upload code and upload the Spring Boot application jar.
At this point, Elastic Beanstalk is going to warn us that our application environment is in a degraded state. Don’t worry about this; we don’t expect things to work properly yet since the configuration is incomplete.
Let’s go ahead and make the required changes. All the changes are made from child pages of the main configuration dashboard shown below:
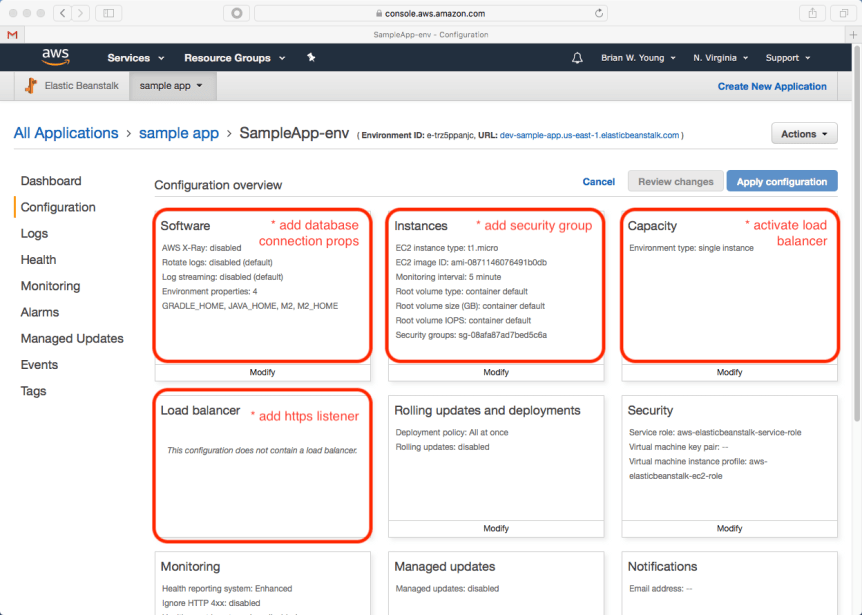
Software Configuration
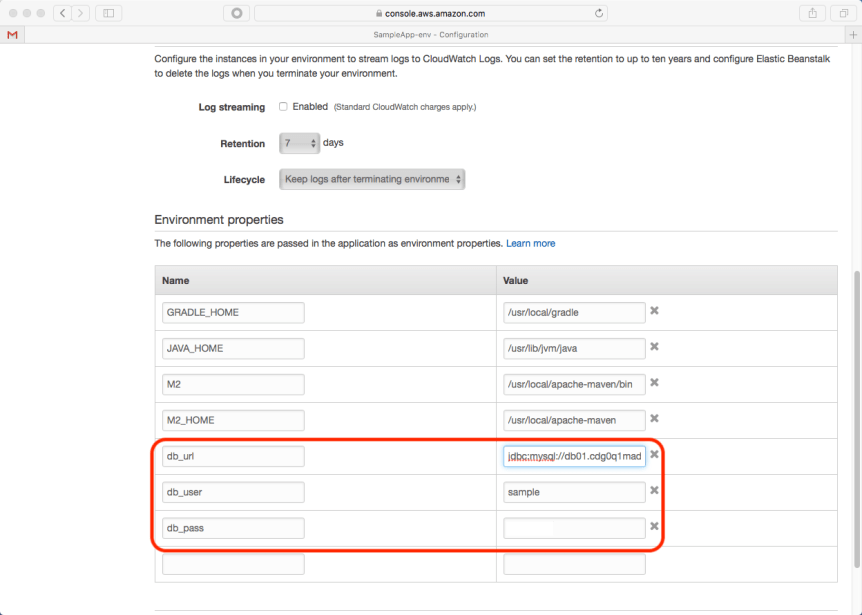
This section allows us to define system properties that are made available to our application. This is useful for environment specific or sensitive properties. For our sample application, we need to define the following:
- db_url: jdbc:mysql://<host>:3306/sample_db (the host is shown in the RDS configuration)
- db_user: the user provided during RDS setup
- db_pass: the password provided during RDS setup
Instances Configuration
To enable our application to communicate with the database, the RDS security group needs to be added. This is the same security group that we modified when configuring RDS.
This is also the configuration area that allows us the change the ec2 instance type. For our sample application, a t1 or t2 micro is sufficient.
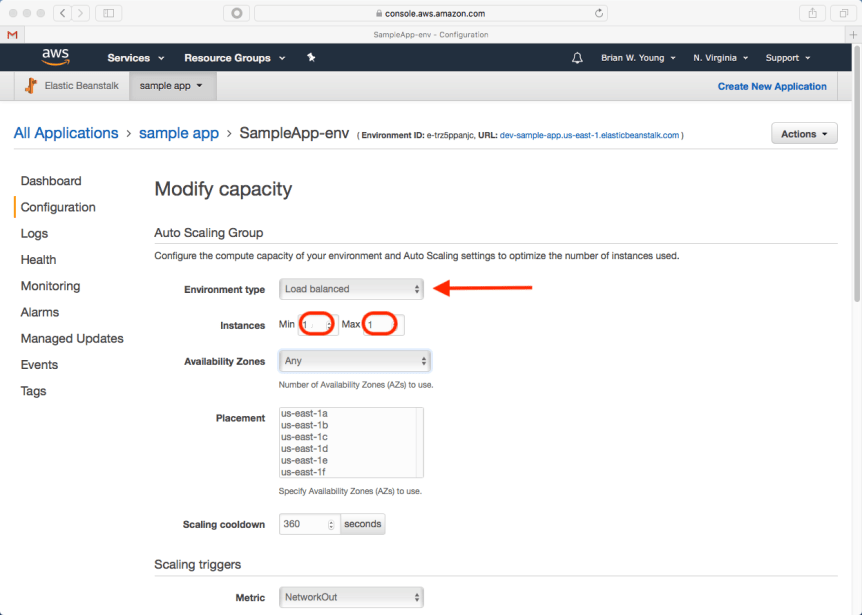
Capacity Configuration
We’ll change our environment to load balanced. The addition of a load balancer gives us a place to establish an https listener. Since we only need one application instance for this example, both the min and max instance counts can be set to 1.
Load Balancer Configuration
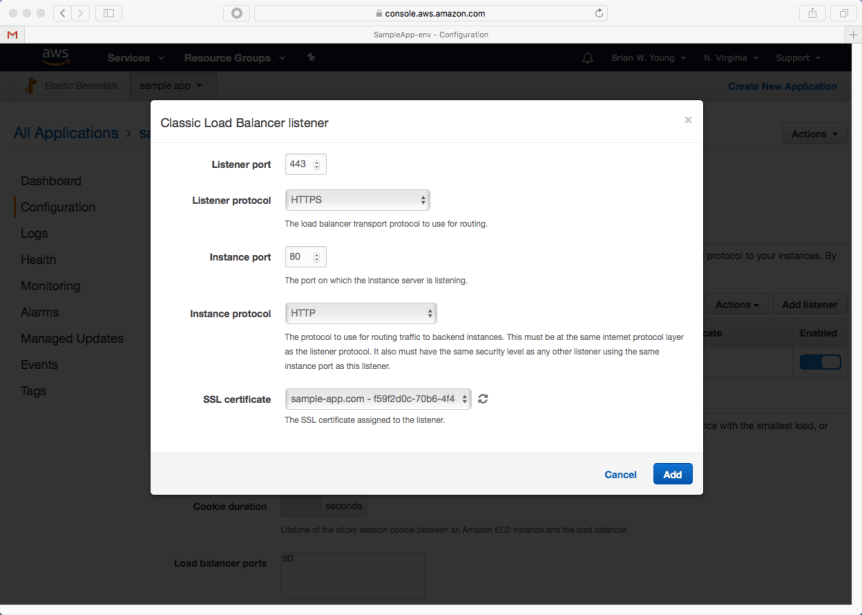
We want our front end to communicate securely with the back end, so we’ll create an https listener and associate our digital certificate with the listener.
- Listener protocol & port: HTTP/443
- Instance protocol & port: HTTP/80*
- SSL certificate: select the SSL certificate created earlier. If you recall, we added an alias to the certificate for api.sample-app.com.
* The Elastic Beanstalk Java environment uses nginx to map our application from port 5000 to port 80. As a result, the load balancer’s listener(s) communicate with our instance over port 80. By default, a Spring Boot application listens on port 8080, but the Beanstalk is expecting 5000. The path of least resistance (seen in our sample app) is to tell Spring Boot to listen on port 5000 instead.
A final note- in production, I recommend removing the http:80 listener from the load balancer since nobody should be communicating with the back end over a non-secure port.
I recommend restarting the environment after making the above configuration changes. The environment should be healthy after the restart.
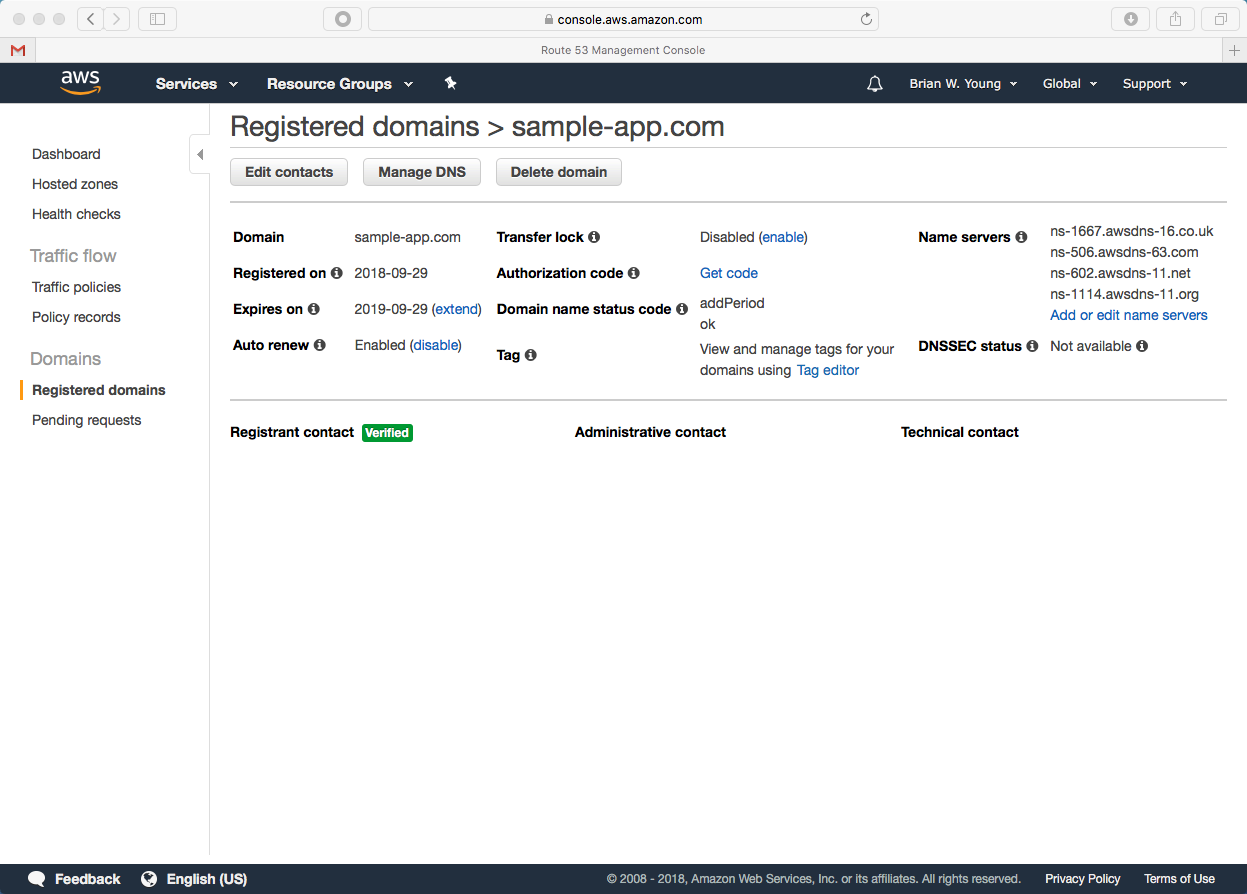
Route 53
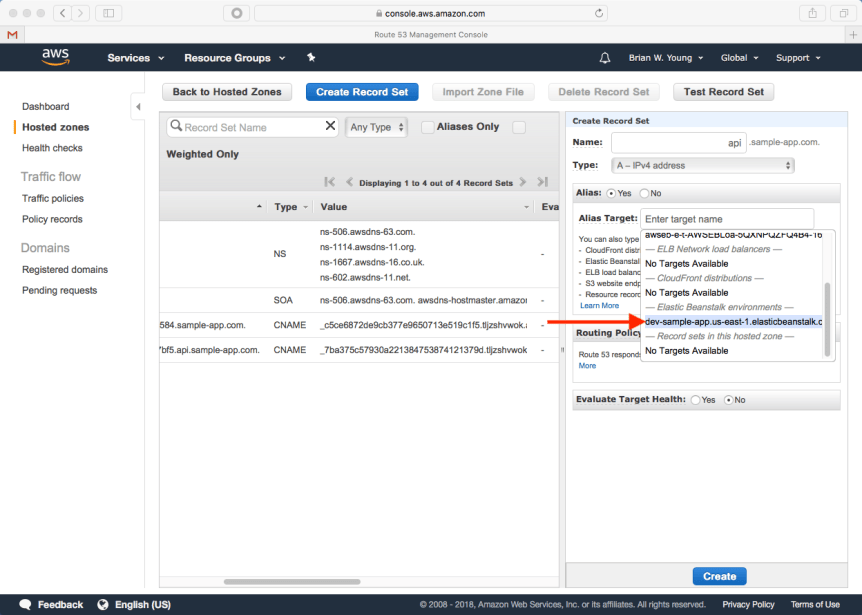
We need to pay a follow up visit to Route 53 to create an alias record that points to our Elastic Beanstalk environment. We couldn’t have done this when we first set up our domain since at that point we didn’t have a Beanstalk environment.
The alias target field allows us to select our Beanstalk environment from a list.
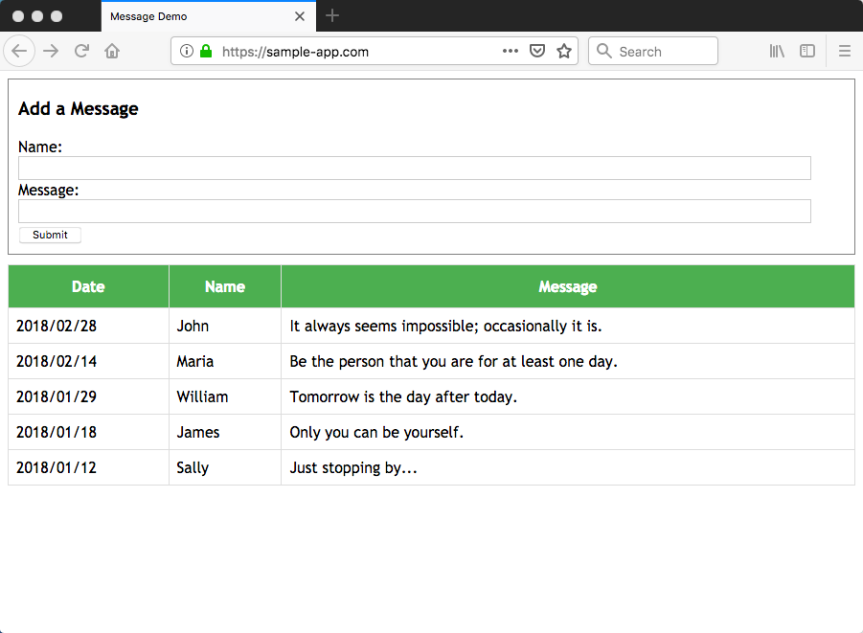
Now we can verify the back end functionality by hitting one of our endpoints in a browser, e.g. https://api.sample-app.com/message:
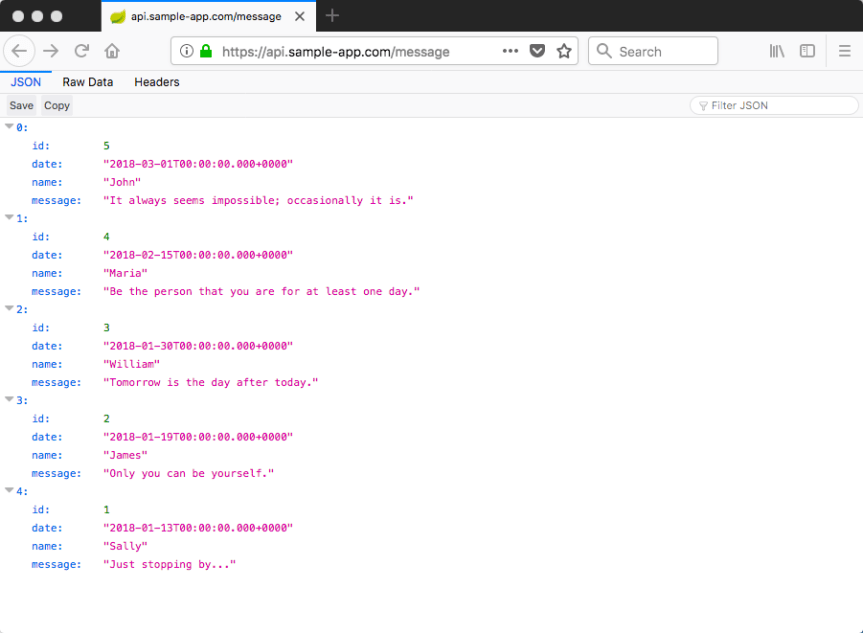 It works 🙂 In my next post, we’ll finish things up by hosting the front end.
It works 🙂 In my next post, we’ll finish things up by hosting the front end.